The Architecture of Replication
This section discusses in-depth how replication and synchronization work. Replication is a critical function that is common to all of the major CA XOsoftв„ў applications, whether they are distributing content, consolidating content, providing a constantly updated backup copy of application data in case of a disaster, or providing continuous application availability through automated monitoring and failover.
How CA XOsoftв„ў Replication (formerly CA XOsoft WANSync) accomplishes replication is the topic of this page. As a point of reference, you may want to also review these sections of our website:
The Basic Concepts of Replication
The purpose of replication is simple: to ensure that data on each replica server is a valid, up-to-date and completely consistent copy of the data on the master. There are three aspects to accomplishing this:
- Capturing or gathering information on the master server
- Transferring the information from the master server to the replica server
- Applying the information on the replica server.
There are actually two quite distinct functions involved in replication:
- Synchronization
Synchronization is the process of bringing the copy of the data on the replica server into sync with that on the master, either by copying the entire set of data, if no part of it yet exists on the replica, or by determining and sending the differences between the datasets in order to minimize the bandwidth and time required. For synchronization, the three phases are:
- Comparing files on the master and replica to determine where they differ
- Transferring the difference data
- Creating or locating the files to be modified on the replica and inserting the transferred information
- Replication
Replication is the ongoing process of capturing changes to the data on the master as they occur and duplicating those changes on the replica copies of the data. Here, the three phases are:
- Monitoring the operation of the file system and capturing writes and other operations that cause changes to the data
- Serializing and transferring the captured operations to the replica servers
- "Replaying" the received operations in the same sequence on the replica server
CA XOsoft Replication supports simultaneous synchronization and replication, rather than requiring that they be separate phases. If it did not, the production server would have to be down throughout the synchronization process, an unacceptable cost for a system designed to prevent downtime in the first place! In our discussion below, however, we will treat them as separate and distinct processes.
The Synchronization Process
Synchronization ensures that a set of folders and files on a replica server involved in a scenario is identical to the set on the master. There are two types of synchronization generally used in CA XOsoft Replication:
- File Synchronization
File synchronization compares files on the source and target servers and, whenever they are different, copies the entire file. It is the method used for file server and content delivery scenarios.
- Block Synchronization
Block synchronization is the method appropriate for database application data, such as Exchange, Oracle or SQL server. The method performs an efficient block-by-block comparison of the source and target files and copies over only those blocks that are different, rather than always requiring the transfer of the entire file.
In both methods, synchronization begins by taking a snapshot of the directories that have been configured in the scenario. A snapshot consists of a point-in-time list of all the directories, sub-directories, file names, file sizes, file modification times and ACLs that have been configured as part of the scenario. The snapshot is performed on both the master and replica servers, since the replica server may well already have a partial copy of the data.
File Synchronization
In file synchronization, the replica server sends its snapshot to the master server, which uses it to drive the remainder of the synchronization process. The comparison may be configured to consider only file size and modification time to determine whether two files differ, or can perform a check of the actual contents of the data. The former approach, which is not valid in the case of a database application, can be a legitimate way to significantly speed up the comparison process on a file server. Either way, the CA XOsoft engine on the master server then sends a sequence of commands to the replica consisting of (a) deletes of files that exist only on the target and (b) the entire file contents of files that either exist only on the master or that exist on the replica but differ from the version on the master.
Block Synchronization
Block synchronization is driven by the replica server, rather than the master server. Once the overall snapshot is computed, the source server sends it to the target. The target server then traverses the files and directories in the snapshot and performs the following operations:
- If the file exists only on the target, delete it if so configured.
- If the file exists only on the source, requests the source server to send entire file.
- If the file exists on both, request the source server to compute a "map" of signatures of all blocks of the file. The target server then traverses this map, computing signatures of blocks in its own copy, and requests that the source send any blocks that are different.
Both of these algorithms are of course implemented so as to achieve maximum efficiency. In addition, the process may be configured, for example, not to delete files that already exist on the target server but do not exist on the source.
The Replication Process
There are two basic types of replication supported by CA XOsoft Replication: scheduled mode and online mode.
Scheduled replication mode is really nothing more than an automatically performed synchronization according to some predetermined schedule, say every few hours or once a day. CA XOsoft Replication's ability to perform synchronization on a live system is obviously critical, but this replication mode does not differ in principle from a synchronization performed as part of initializing replication. Here we will focus on online replication.
Online replication is the mode in which all changes are captured as they occur on the master server and transferred to be replayed on the replica server in precisely the same sequence.
In contrast to synchronization, which can be implemented as a normal application within the operating system, replication must be intimately tied into the operating and file systems since it must monitor modifications to data as they occur, rather than simply checking files periodically. For this reason, we will discuss both the internal working of the CA XOsoft Replication system and offer a brief introduction to how applications, the OS and the file system all interact and how CA XOsoft Replication and other similar applications plug in.
As described above, the replication process consists of three distinct components: capture on the master, transfer over the network, and application on the replica. The most complex part of this process is the capture on the master.
Capturing Changes: The Interaction of OS, File system, and CA XOsoft Replication
Modern server operating systems are organized in a layered fashion like that shown below.
At the top is the user layer or user mode. This is the layer that runs core applications like Exchange, SQL Server or Oracle, business application infrastructure like SAP, or higher-level business applications like a CRM system. Applications remain in user mode until they need to access a shared external resource like storage or networking hardware. At this point, the application makes a system call, a command that specifies what the application wishes to do with the external resource, and passes control to the operating system in the kernel layer.
The kind of system call that is of interest for replication is an operation addressing storage or disk. In most cases, a storage call is not a direct access to a disk вҖ” very few applications ever directly manipulate raw disk devices. Normally, applications read and write data in files through a file system, an operating system function that organizes data stored on disks into files and directories, or folders, and provides a much simpler and more flexible set of methods for accessing and changing data than would be the case if all applications were independently attempting to manipulate blocks of data on a disk directly.
Between the application and file system layers is a special layer that is used to accommodate low-level functionality like replication. In the Windows operating system, for example, a file system call passes through the IFS stack, a collection of components that all operate, one after another, on the data and commands passing through from the application to the file system, then goes to the NTFS file system, which then passes any actual disk operations to the disk I/O subsystem. Once the write to the disk device occurs, a confirmation then travels all the way back up through all the layers until, finally, it is passed in the appropriate form back to the application, either in a chunk of data read or an indication of the success or failure of the requested operation. An analogous mechanism operates in UNIX and Linux systems.
The IFS stack and UNIX equivalent are where XOFS, the file system filter driver component of CA XOsoft Replication, sits. The idea behind this stack is precisely to allow the installation of new components, like XOFS, that extend or modify the functionality of the file system. This is the standard mechanism for supporting a wide variety of critical extended functionality such as encryption, virus scanning, compression, and, of course, replication, to name just a few common examples.
Let's consider what happens with a write example. When the operating system passes the write request to the XOFS file system filter driver, XOFS inspects the request to see what, if anything, it must do with it. From the point of view of replication, the only characteristic of an I/O operation that matters is whether it changes the data in any way. If it does, the change must be replicated on all copies of the data; if not, the operation should simply be passed through.
It is very important to understand that a replication filter like XOFS does not change the operation or the data in any way вҖ” it simply makes a copy of the operation and any associated data so that it can repeat the operation on the replica server. Once the copy is made, the operation is passed on unchanged for handling by any remaining filters and by the file system. Once the operation has been completed at the lowest level, communication travels in the opposite direction back up the chain with either confirmation that the operation has been completed or with an error condition. Of course, CA XOsoft Replication does not actually carry out the replication of the operation until notification comes that it has successfully completed.
A vital characteristic of the CA XOsoft Replication replication system is that write order within all files participating in a scenario is always strictly preserved, regardless of whether the writes occur in the same or different files, the same or different folders, the same or different volumes or disks. Without this characteristic, valid replication of databases, mail servers and many other applications would not be possible.
Transferring Changes: Moving Information Over the Network
This is the simplest part of replication.
Once an operation has been captured and a copy made, it must be transferred to the replica server. This aspect of replication is controlled by the CA XOsoft engine, which is the user-mode component of CA XOsoft Replication that runs on both the master and replica servers.
It is in this stage that the asynchronous nature of the replication becomes apparent. While XOFS captures operational data as it is being written, it does not delay the completion of the operation on the master in any way. In addition, in order to efficiently utilize the bandwidth available, the CA XOsoft engine accumulates operations into chunks for sending over the network. In the end, the resulting lag is minimal, typically on the order of a few seconds. When combined with the principle that order of operations is preserved, in effect, the data on the replica are identical to what existed on the master at some slightly earlier point in time.
Accumulated data may be transferred as is, or may be first compressed. In addition, CA XOsoft Replication allows bandwidth usage to be regulated on either a constant or scheduled basis вҖ” if bandwidth throttling is on, the CA XOsoft engine will regulate the rate at which data is transferred in order to ensure that it does not violate bandwidth usage restrictions.
An additional key capability of the CA XOsoft engine in this phase of replication is its ability to tolerate the temporary disconnections that often characterize WAN links. Should disconnection occur, as long as it does not persist longer than CA XOsoft Replication has been configured to wait, the engine will simply continue to accumulate data until the link is restored, whereupon it will transfer all accumulated data, in order, over the network to the replica.
Applying Changes: Recreating the data on the Replica Server
The final aspect of the replication process concerns what happens to replication journals that are received on the replica server. As chunks of operations and data, called replication journals, are received on the replica, the CA XOsoft engine running there places them into a spool directory for execution, where they can be held temporarily, for example, if Assured Recovery testing is in progress.
Execution of journals that have been received from the master is completely straightforward in the case of an entirely passive replica. Journal entries consist of normal file operations like writes, renames, creates and deletes. These are simply performed, as specified, in the order specified. Since the replica is passive, there is no possibility of conflict with other processes in accessing the files вҖ” CA XOsoft Replication is the only process involved in modifying the files and folders being replicated and no process is involved in reading them.
Execution of journals in a CA XOsoft Content Distribution (formerly CA XOsoft WANSyncCD) scenario is potentially more complex since it can happen that a file that is to be updated is being read by another process (e.g., on a web server) and perhaps is even locked so that CA XOsoft Replication is unable to update it. This situation is handled gracefully by the replicate-on-close mode mentioned earlier.
Built-In CDP: Creating Rewind Journals
CA XOsoft's replication products are unique in offering built-in continuous data protection, or CDP, through embedded rewind technology. Rewind enables recovery even in the event corruption of the data occurs on the master server (and is of course replicated to the replica server) by allowing the data on the replica to be rewound to any previous consistent state.
Continuous data protection has emerged as one of the leading growth areas of data protection and data recovery software. CDP is the ability to recover data not just to certain isolated previous states captured, for example, in a daily or weekly backup or snapshot, but to recover the data back to any point in time. CA XOsoft pioneered the development of true, continuous CDP back in 2002 as an integrated capability in CA XOsoft Replication.
Underlying CA XOsoft's rewind technology is the creation of rewind journals during replay on the replica. The idea is simple and is essentially the reverse of replication. In replication, file and folder modification events are captured as they occur and recorded precisely in a replication journal so that they can be "replayed" on another server to duplicate the changes. A rewind journal is also intended for replay, but what is recorded there is not the original operation, but the inverse operation. In other words, the rewind journal records the operation that will undo whatever the original operation was, as illustrated in Figure X below. Thus, for example, if an operation writes 8K bytes to the end of a file, XOFS will record an operation to "unwrite" those 8K bytes and to restore the original content. Similar "undo" operations are recorded for every other kind of operation.
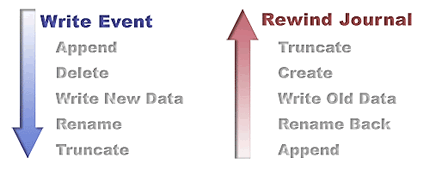 When the journal is replayed during a recovery the effect is to cancel each of the events that originally occurred, one by one, in the proper order, in order to restore the file to the state at any previous time.
Next topic: The Architecture of High Availability
|